
이번에는 페이지 스크롤 기능을 사용하여 로딩되는 대상들을 크롤링해 보았다.
생각보다 뜻대로 되지 않아 오래 걸렸다..
스크롤 방법
스크롤 방법에는 간단하게 3가지 방법이 있다고 한다.
1. 페이지의 높이를 계산해서 최하단으로 이동하는 방법.
2. 키보드의 PAGE_DOWN이나 END, 아래 화살표 키를 반복적으로 눌러 페이지를 내려가는 방법
3. ActionChains의 move_to_element를 이용하여 하단의 요소로 이동하는 방법
1번은 로딩시간이 걸릴 때 오류가 생길 수 있기 때문에 시간 텀을 주어야 한다.
3번은 크롤링할 대상인 페이지에서 최하단의 요소를 찾기 힘들었다..
따라서 2번의 방법으로 구현해 보았다.
from selenium.webdriver.common.keys import Keys
import time먼저 필요한 모듈들을 넣어준다.
Keys는 입력할 키값을 쉽게 사용할 수 있도록 한다.
time은 원활한 크롤링을 위해 대기시간을 주기 위해 사용한다.
actions = driver.find_element(By.CSS_SELECTOR, 'body')먼저 스크롤을 하기 위해서는 element를 선택해 주어야 한다.
actions.send_keys(Keys.END)선택한 요소에서 send_keys 메서드를 사용해 원하는 입력을 넣을 수 있다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
links_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > a"
driver.get(url)
actions = driver.find_element(By.CSS_SELECTOR, 'body')
time.sleep(2)
actions.send_keys(Keys.END)
time.sleep(2)
actions.send_keys(Keys.END)
time.sleep(2)최종적으로 구현한 해당 코드에서 스크롤이 정상적으로 작동하는 것을 확인할 수 있다.
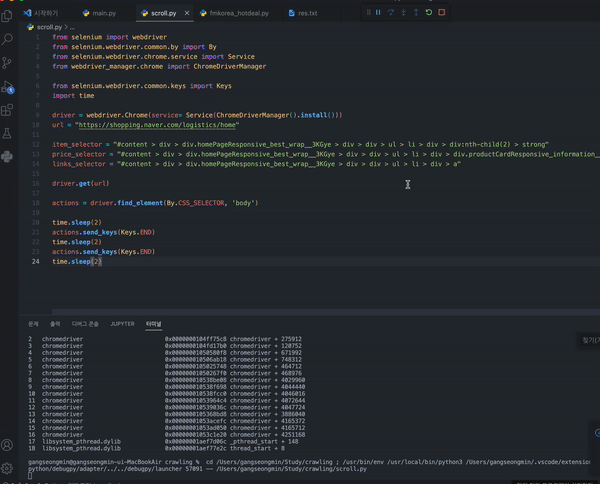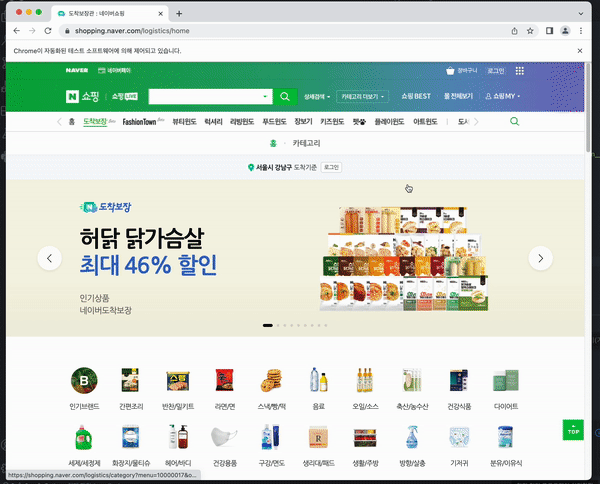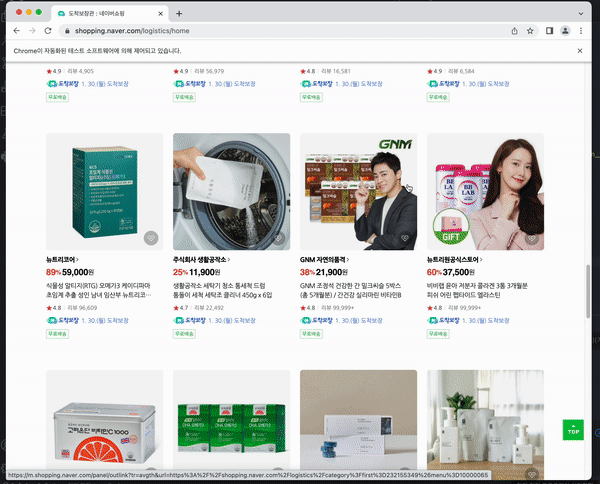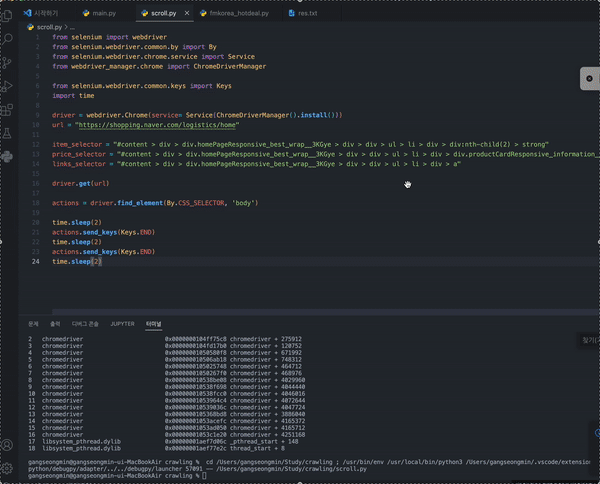
최종 코드
위 스크롤 기능과 크롤링 기능을 묶어 함수로 만들어 주었다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
links_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > a"
driver.get(url)
actions = driver.find_element(By.CSS_SELECTOR, 'body')
def crawling(count):
items, prices, links = [], [], []
for _ in range(count):
for i in driver.find_elements(By.CSS_SELECTOR, item_selector):
items.append(i.text)
for i in driver.find_elements(By.CSS_SELECTOR, price_selector):
prices.append(i.text)
for i in driver.find_elements(By.CSS_SELECTOR, links_selector):
links.append(i.get_attribute("href"))
actions.send_keys(Keys.END)
time.sleep(2)
return items, prices, links
items, prices, links = crawling(2)
print("가져온 상품 수: ", len(items))
for item, price, link in zip(items, prices, links):
print("상품: ", item)
print("가격: ", price)
print("주소: ", link)
print()로딩 시간을 원활하게 하기 위해 페이지 스크롤마다 2초의 텀을 두었다.
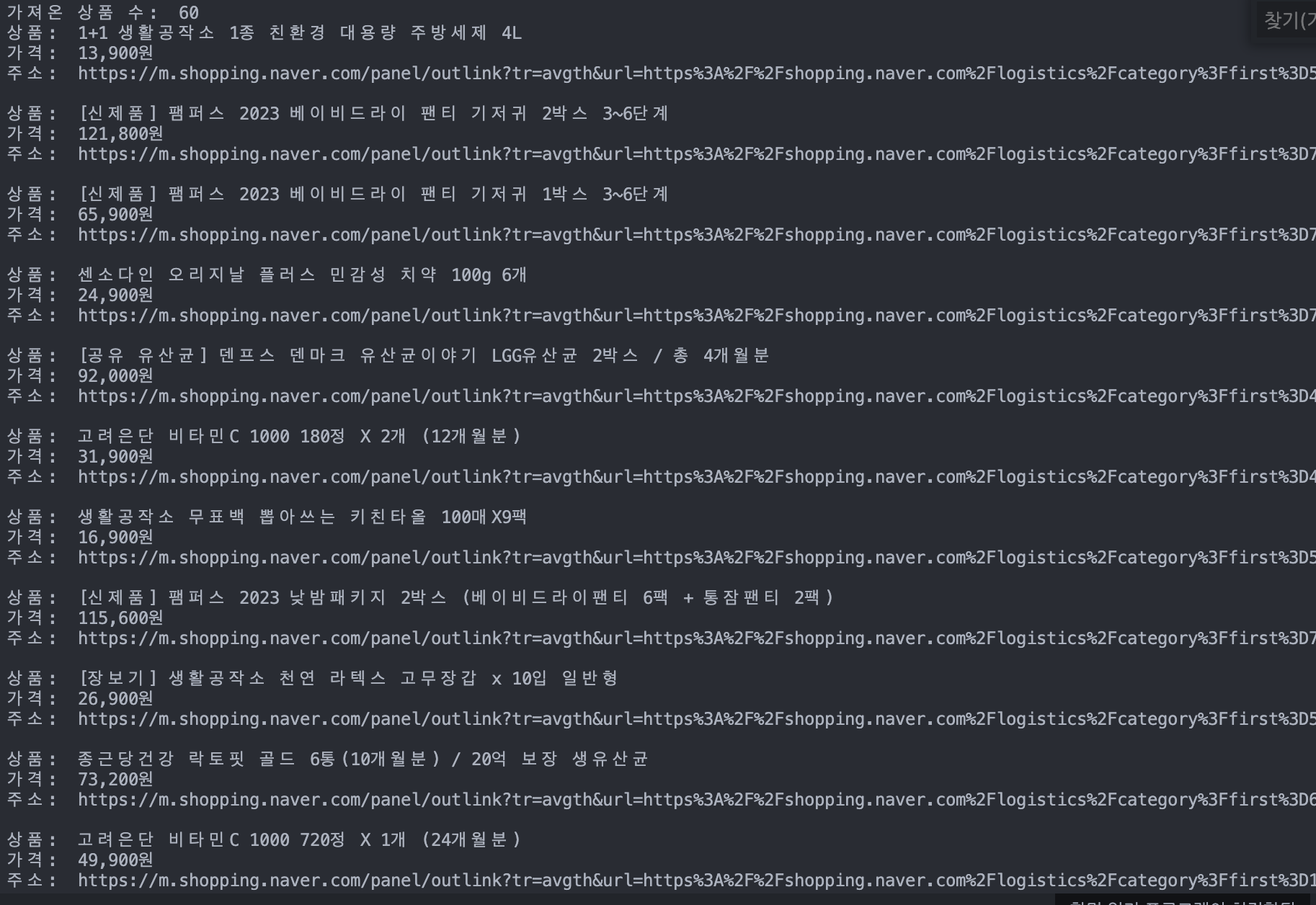
1회 크롤링의 20개가 아닌 60개의 크롤링 결과를 확인할 수 있다.
고생했던 부분 "stale element reference: element is not attached to the page document" 오류
위 코드를 자세히 보면 "크롤링 -> 크롤링 데이터를 모두 읽어서 리스트에 삽입" 과정을 반복한다.
사실 Text를 매번 추출하지 않고 크롤링 선택된 데이터를 리스트에 추가적으로 담아 사용하려 했다.
하지만 "stale element reference: element is not attached to the page document" 해당 오류가 발생했다.
이는 크롤링한 대상이 무한 스크롤에 페이지가 넘어가게 되어 추출할 수 없었다.
즉, 1번 크롤링에 추출한 뒤 원하는 정보를 뽑아놓지 않으면 2번 크롤링에 스크롤하는 과정에서 날아가 버린다.
실제로 개발자 도구를 열어 스크롤해 보면 데이터가 20~40개만 유지되고 이전 데이터는 사라진다.
따라서 매번 크롤링한 요소의 데이터를 뽑아 저장시켜 주어야 한다.
보완할 부분
평소에는 20개 단위로 크롤링이 된다.
END를 사용해서 스크롤을 내리다 보면 일정 부분에서 40개의 요소가 찾아진다.
따라서 위의 코드를 사용하면 중복으로 크롤링된 데이터를 확인할 수 있다.
이를 해결하려고 많이 찾아보았지만 아직 해결하진 못했다..
'Study > Python' 카테고리의 다른 글
| 네이버 Clova AI OCR API를 사용해보자. (1) (0) | 2023.05.09 |
|---|---|
| [Python] 파이썬 코딩테스트 시간 단축하기 (0) | 2023.01.31 |
| Selenium을 활용한 동적 크롤링 링크 주소 가져오기 (0) | 2023.01.26 |
| Selenium을 활용한 네이버 쇼핑 품목 동적 크롤링 (0) | 2023.01.25 |
| [mac] m1 웹 크롤링 Selenium, Chromedriver 설치하기 (1) | 2023.01.22 |
이번에는 페이지 스크롤 기능을 사용하여 로딩되는 대상들을 크롤링해 보았다.
생각보다 뜻대로 되지 않아 오래 걸렸다..
스크롤 방법
스크롤 방법에는 간단하게 3가지 방법이 있다고 한다.
1. 페이지의 높이를 계산해서 최하단으로 이동하는 방법.
2. 키보드의 PAGE_DOWN이나 END, 아래 화살표 키를 반복적으로 눌러 페이지를 내려가는 방법
3. ActionChains의 move_to_element를 이용하여 하단의 요소로 이동하는 방법
1번은 로딩시간이 걸릴 때 오류가 생길 수 있기 때문에 시간 텀을 주어야 한다.
3번은 크롤링할 대상인 페이지에서 최하단의 요소를 찾기 힘들었다..
따라서 2번의 방법으로 구현해 보았다.
from selenium.webdriver.common.keys import Keys
import time먼저 필요한 모듈들을 넣어준다.
Keys는 입력할 키값을 쉽게 사용할 수 있도록 한다.
time은 원활한 크롤링을 위해 대기시간을 주기 위해 사용한다.
actions = driver.find_element(By.CSS_SELECTOR, 'body')먼저 스크롤을 하기 위해서는 element를 선택해 주어야 한다.
actions.send_keys(Keys.END)선택한 요소에서 send_keys 메서드를 사용해 원하는 입력을 넣을 수 있다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
links_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > a"
driver.get(url)
actions = driver.find_element(By.CSS_SELECTOR, 'body')
time.sleep(2)
actions.send_keys(Keys.END)
time.sleep(2)
actions.send_keys(Keys.END)
time.sleep(2)최종적으로 구현한 해당 코드에서 스크롤이 정상적으로 작동하는 것을 확인할 수 있다.
최종 코드
위 스크롤 기능과 크롤링 기능을 묶어 함수로 만들어 주었다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
links_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > a"
driver.get(url)
actions = driver.find_element(By.CSS_SELECTOR, 'body')
def crawling(count):
items, prices, links = [], [], []
for _ in range(count):
for i in driver.find_elements(By.CSS_SELECTOR, item_selector):
items.append(i.text)
for i in driver.find_elements(By.CSS_SELECTOR, price_selector):
prices.append(i.text)
for i in driver.find_elements(By.CSS_SELECTOR, links_selector):
links.append(i.get_attribute("href"))
actions.send_keys(Keys.END)
time.sleep(2)
return items, prices, links
items, prices, links = crawling(2)
print("가져온 상품 수: ", len(items))
for item, price, link in zip(items, prices, links):
print("상품: ", item)
print("가격: ", price)
print("주소: ", link)
print()로딩 시간을 원활하게 하기 위해 페이지 스크롤마다 2초의 텀을 두었다.
1회 크롤링의 20개가 아닌 60개의 크롤링 결과를 확인할 수 있다.
고생했던 부분 "stale element reference: element is not attached to the page document" 오류
위 코드를 자세히 보면 "크롤링 -> 크롤링 데이터를 모두 읽어서 리스트에 삽입" 과정을 반복한다.
사실 Text를 매번 추출하지 않고 크롤링 선택된 데이터를 리스트에 추가적으로 담아 사용하려 했다.
하지만 "stale element reference: element is not attached to the page document" 해당 오류가 발생했다.
이는 크롤링한 대상이 무한 스크롤에 페이지가 넘어가게 되어 추출할 수 없었다.
즉, 1번 크롤링에 추출한 뒤 원하는 정보를 뽑아놓지 않으면 2번 크롤링에 스크롤하는 과정에서 날아가 버린다.
실제로 개발자 도구를 열어 스크롤해 보면 데이터가 20~40개만 유지되고 이전 데이터는 사라진다.
따라서 매번 크롤링한 요소의 데이터를 뽑아 저장시켜 주어야 한다.
보완할 부분
평소에는 20개 단위로 크롤링이 된다.
END를 사용해서 스크롤을 내리다 보면 일정 부분에서 40개의 요소가 찾아진다.
따라서 위의 코드를 사용하면 중복으로 크롤링된 데이터를 확인할 수 있다.
이를 해결하려고 많이 찾아보았지만 아직 해결하진 못했다..
'Study > Python' 카테고리의 다른 글
| 네이버 Clova AI OCR API를 사용해보자. (1) (0) | 2023.05.09 |
|---|---|
| [Python] 파이썬 코딩테스트 시간 단축하기 (0) | 2023.01.31 |
| Selenium을 활용한 동적 크롤링 링크 주소 가져오기 (0) | 2023.01.26 |
| Selenium을 활용한 네이버 쇼핑 품목 동적 크롤링 (0) | 2023.01.25 |
| [mac] m1 웹 크롤링 Selenium, Chromedriver 설치하기 (1) | 2023.01.22 |