
이전 게시물에서 기본 환경 세팅을 완료했다.
이번에는 셀레니움을 활용해서 최근 네이버에서 새롭게 시작한 서비스인 도착 보장 서비스의 인기 품목과 가격을 크롤링해보자.
1. 크롤링할 태그 찾기
크롤링을 하기 위해서는 원하는 품목의 위치를 찾아주어야 한다.
먼저 네이버 쇼핑 실시간 도착보장 홈페이지를 들어가 보자.

다음과 같이 품목들이 나열되어 있고, 스크롤을 하게 되면 더 많은 품목이 로드된다.
나는 css_selector를 통해 크롤링할 품목을 검색해 보았다.
먼저 F12를 통해 개발자 도구를 열어준다.

다음과 같이 개발자 도구 창을 뜬다면 크롤링할 요소를 찾아줄 도구를 선택한다.
우측 개발자 도구의 최상단 가장 왼쪽의 마우스 모양의 아이콘을 클릭해 주면 된다. (단축키 Control + Shift + C)

크롤링할 부분을 가져다 놓으면 다음과 같이 해당 부분이 표시된다.
보통 품목이름 "풀무원 NEW 얇은 피... " 해당 부분이 선택되는데 전체 컨테이너가 선택된다.
이는 어차피 내부에서 찾을 수 있으니 일단 해당 부분을 선택하고 해당 위치의 div 태그 내에서 품목 이름의 위치를 찾아본다.

해당 부분을 찾은 뒤 우클릭 -> 복사 -> selector 복사를 선택하면 해당 위치를 찾을 수 있다.
이외에도 XPath를 통해 해당 위치를 찾는 방법이 있지만 나는 selector를 통해 크롤링해보았다.
복사된 셀렉터를 보면 "#\37 668773367" 다음과 같이 복사된다.
여러 품목을 복사해 와야 하기 때문에 규칙을 찾아야 한다.
따라서 옆에 품목의 이름의 셀렉터로 복사해 보았다.
# 풀무원 만두
#\36 886776790
# 드시모네
#\37 668773367
하지만 둘의 공통점은 찾을 수 없었다.
이는 id를 통해 셀레터가 선택되었기 때문이다.
html을 조금 둘러본 뒤 품목들은 ul 밑에 li 태그로 순차적으로 표현되어 있음을 알 수 있었다.

li 태그를 담고 있는 ul 태그를 찾았고, 해당 셀렉터를 복사해 보았다.
#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul
다음과 같이 태그를 찾을 수 있었다.
하지만 내가 필요한 건 ul > li > div > 두 번째 div > strong에 해당하는 요소이다.
즉 위의 셀렉터를 최종적으로
#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong
다음과 같이 구해주었다. 여기서 nth-child(2)란 두 번째 div를 의미한다.
추가적으로 두번째 div의 class 태그를 살펴보면
productCardResponsive_information__1HK4_
해당 값으로 모든 품목이 동일한 값을 가짐을 볼 수 있다.
따라서
#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > strong
해당 셀렉터를 사용해도 크롤링이 가능하다.
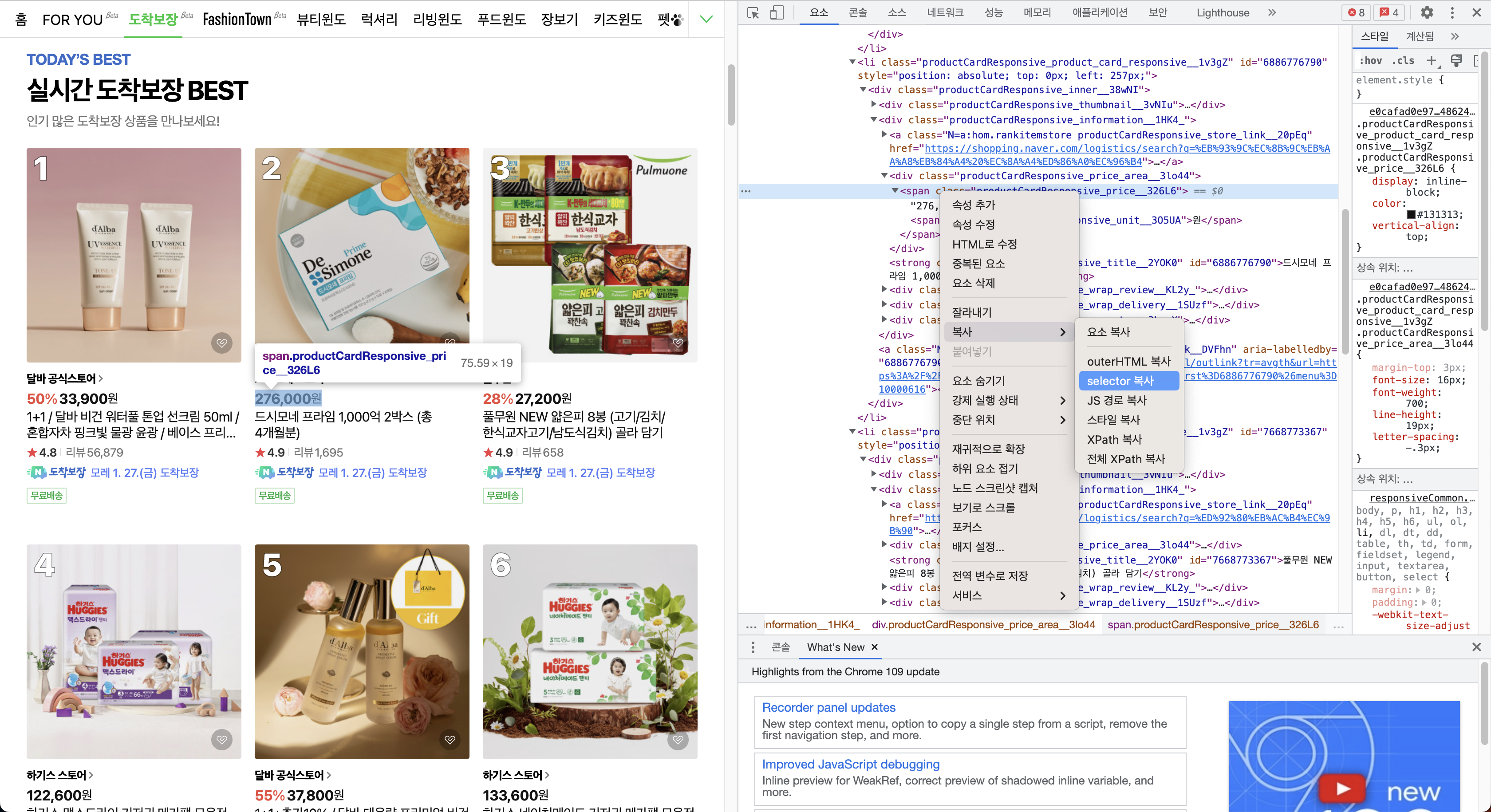
마찬가지로 가격의 셀렉터로 구할 수 있다.
다음과 같이 복사를 하면
#\35 750426971 > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span
다음과 같은 셀렉터를 구할 수 있다.
마찬가지로 \35 750426971 부분은 id 값이므로 공통된 셀렉터로 변경해 준다.
최종 가격의 셀렉터
#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span
2. 크롤링하기
먼저 필요한 모듈을 import 하고 기본 세팅을 해준다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
1번에서 구한 크롤링할 css 셀렉터도 세팅해 준다.
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
driver의 url을 지정한다.
driver.get(url)
url을 성공적으로 지정했으니 필요한 크롤링을 해준다.
이때 요소의 전체를 가져오는 find_elements를 사용해 주었다. (find_element는 가장 첫 번째로 찾는 하나의 요소를 가져온다.)
나는 css_seletor를 통해 요소를 찾기 때문에 다음과 같은 코드를 작성했다.
items = driver.find_elements(By.CSS_SELECTOR, item_selector)
prices = driver.find_elements(By.CSS_SELECTOR, price_selector)
다른 방식으로 크롤링하거나 추가적인 함수는 다음 문서를 참고하면 된다.
https://selenium-python.readthedocs.io/index.html
이후 출력을 위한 코드를 작성해 주었다.
찾은 요소의 Text 부분을 출력하기 위해서 ".text" 를 통해 해당 요소의 텍스트 부분을 출력할 수 있다.
최종코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
url = "https://shopping.naver.com/logistics/home"
item_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div:nth-child(2) > strong"
price_selector = "#content > div > div.homePageResponsive_best_wrap__3KGye > div > div > ul > li > div > div.productCardResponsive_information__1HK4_ > div.productCardResponsive_price_area__3lo44 > span"
driver.get(url)
items = driver.find_elements(By.CSS_SELECTOR, item_selector)
prices = driver.find_elements(By.CSS_SELECTOR, price_selector)
print("가져온 상품 수: ", len(items))
for item, price in zip(items, prices):
print("상품: ", item.text)
print("가격: ", price.text)
print()
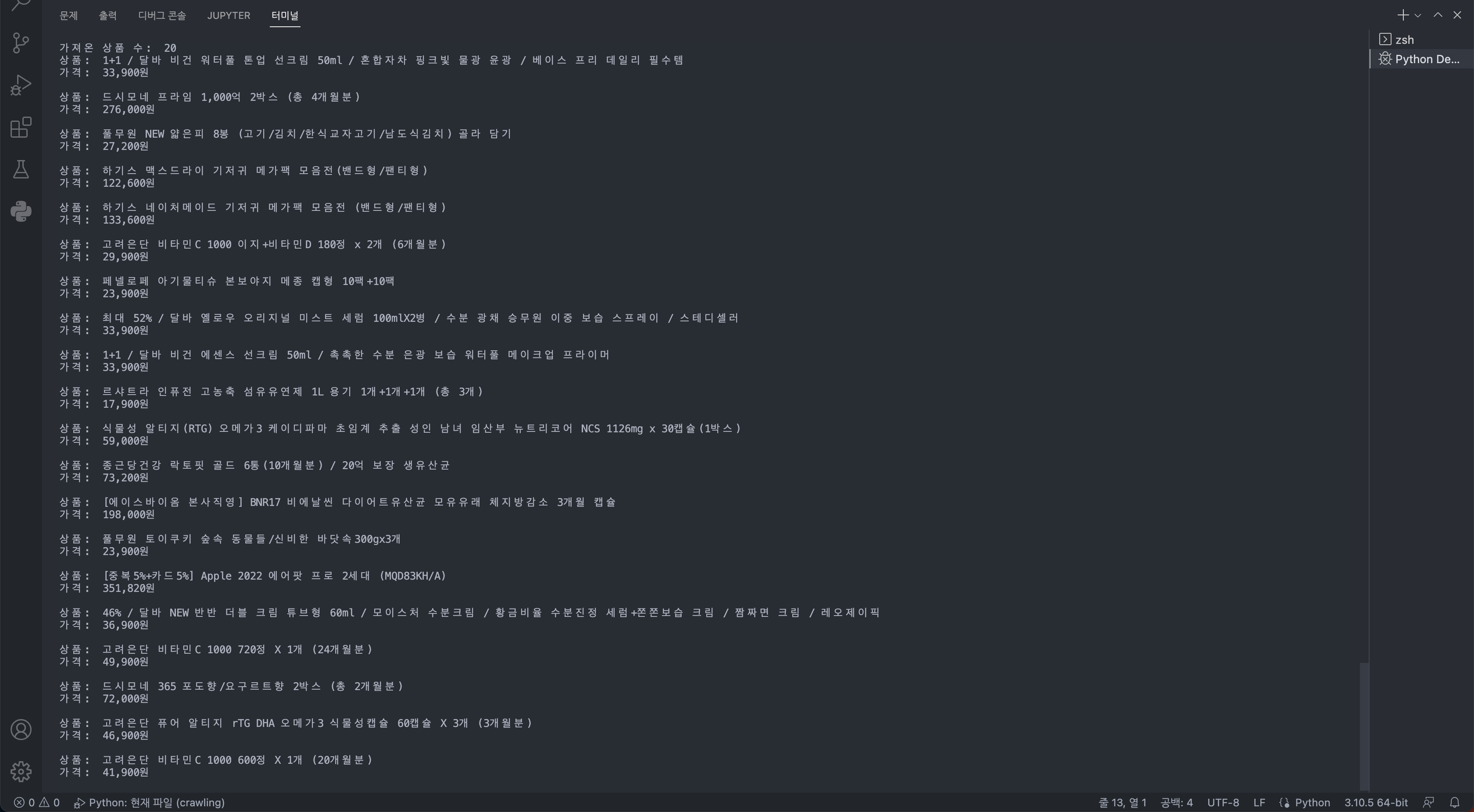
짜잔 정상적으로 크롤링된 결과를 볼 수 있다!
크롤링 대상의 반복적인 규칙을 통해 css 셀렉터를 잘 찾는다면 크롤링을 하는 건 어렵지 않은 것 같다!
다음번엔 a태그를 찾아 링크를 크롤링하고, 셀레니움 기능을 통해 무한 크롤링을 해볼 예정이다!
'Study > Python' 카테고리의 다른 글
| [Python] 파이썬 코딩테스트 시간 단축하기 (0) | 2023.01.31 |
|---|---|
| [Selenium] 페이지를 스크롤하며 무한 크롤링 하기 (0) | 2023.01.27 |
| Selenium을 활용한 동적 크롤링 링크 주소 가져오기 (0) | 2023.01.26 |
| [mac] m1 웹 크롤링 Selenium, Chromedriver 설치하기 (1) | 2023.01.22 |
| [파이썬] 2차원 이상 배열 다중 조건으로 정렬하기 (0) | 2022.11.17 |